
Use Apache Airflow to manage cron jobs
7/21/2023, 12:48:00 PM
tags: airflow cronjob
What is Apache Airflow
Apache Airflow™ is an open-source platform for developing, scheduling, and monitoring batch-oriented workflows.
source: https://airflow.apache.org/docs/apache-airflow/stable/index.html
Why Apache Airflow
| -- | Crontab | Apache Airflow |
|---|---|---|
| Advantage | - Easy to learn | - Rich web interface - Scalability - Graphic work flow |
| Disadvantage | - Hard to manage when job increase - Job dependency is implicit inside code base |
- Steep learning curve |
Architecture

A scheduler, which handles both triggering scheduled workflows, and submitting Tasks to the executor to run.
An executor, which handles running tasks. In the default Airflow installation, this runs everything inside the scheduler, but most production-suitable executors actually push task execution out to workers.
A webserver, which presents a handy user interface to inspect, trigger and debug the behaviour of DAGs and tasks.
A folder of DAG files, read by the scheduler and executor (and any workers the executor has)
A metadata database, used by the scheduler, executor and webserver to store state.
Core Concepts
-
DAG
A DAG (Directed Acyclic Graph) is the core concept of Airflow, collecting Tasks together, organized with dependencies and relationships to say how they should run.
source: https://airflow.apache.org/docs/apache-airflow/stable/core-concepts/dags.html
DAG is a set of tasks and describe workflow of tasks. The following are a example of DAG.
from datetime import datetime from airflow import DAG from airflow.decorators import task from airflow.operators.bash import BashOperator # A DAG represents a workflow, a collection of tasks with DAG(dag_id="demo", start_date=datetime(2022, 1, 1), schedule="0 0 * * *") as dag: # Tasks are represented as operators hello = BashOperator(task_id="hello", bash_command="echo hello") @task() def airflow(): print("airflow") # Set dependencies between tasks hello >> airflow() -
Task
A Task is the basic unit of execution in Airflow. Tasks are arranged into DAGs, and then have upstream and downstream dependencies set between them into order to express the order they should run in.
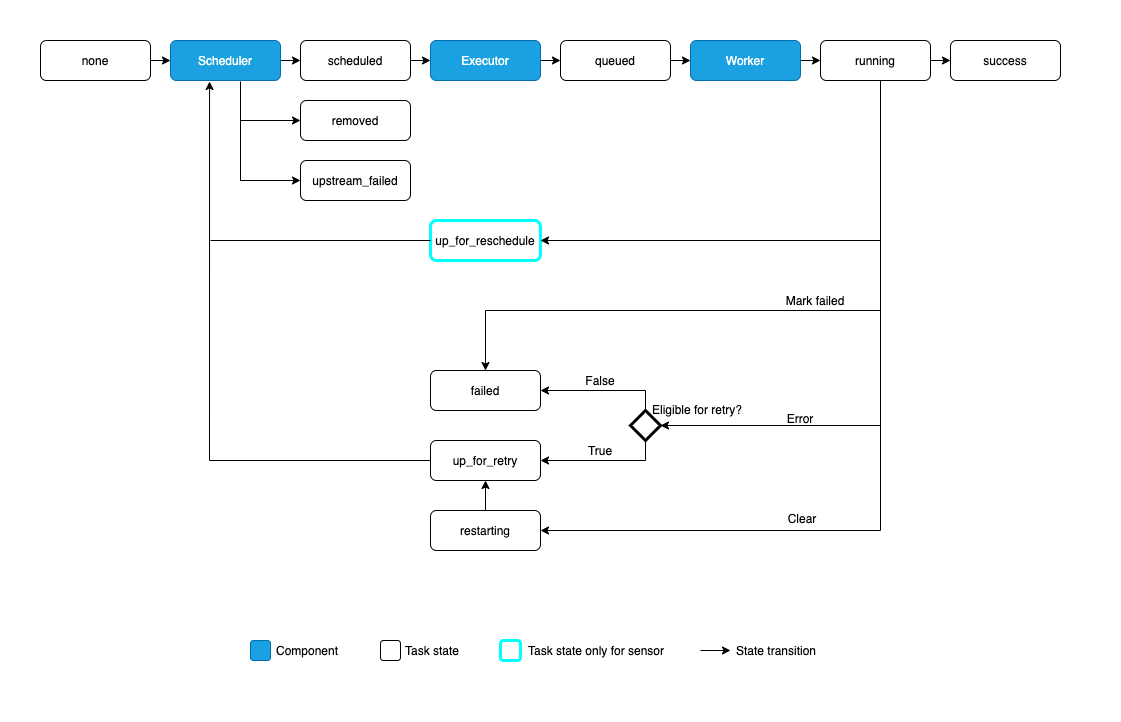 source: https://airflow.apache.org/docs/apache-airflow/stable/core-concepts/tasks.html
source: https://airflow.apache.org/docs/apache-airflow/stable/core-concepts/tasks.html
-
Operator
An Operator is conceptually a template for a predefined Task, that you can just define declaratively inside your DAG:
source: https://airflow.apache.org/docs/apache-airflow/stable/core-concepts/operators.html
For example, you could define a task by BashOperator
from datetime import datetime from airflow import DAG from airflow.decorators import task from airflow.operators.bash import BashOperator # A DAG represents a workflow, a collection of tasks with DAG(dag_id="demo", start_date=datetime(2022, 1, 1), schedule="0 0 * * *") as dag: # Tasks are represented as operators hello = BashOperator(task_id="hello", bash_command="echo hello") # Set dependencies between tasks hello -
XComs
XComs (short for “cross-communications”) are a mechanism that let Tasks talk to each other, as by default Tasks are entirely isolated and may be running on entirely different machines.
source: https://airflow.apache.org/docs/apache-airflow/stable/core-concepts/xcoms.html
Here's the example for Xcom.
from datetime import datetime from airflow import DAG from airflow.decorators import task from airflow.operators.bash import BashOperator # A DAG represents a workflow, a collection of tasks with DAG(dag_id="xcom_test", start_date=datetime(2022, 1, 1), schedule="0 0 * * *", catchup=False) as dag: @task() def airflow(**kwargs): task_instance = kwargs["ti"] task_instance.xcom_push("xcom_data", "send from xcom") # Tasks are represented as operators hello = BashOperator(task_id="hello", bash_command="echo {{task_instance.xcom_pull(task_ids='airflow', key='xcom_data')}}") # Set dependencies between tasks airflow() >> helloThe xcom messages are saved in metadata database. Therefore, when the message is large, it is recommanded communicate by remote storages such as S3, HDFS, etc.
-
Variables
Variables are Airflow’s runtime configuration concept - a general key/value store that is global and can be queried from your tasks, and easily set via Airflow’s user interface, or bulk-uploaded as a JSON file.
source: https://airflow.apache.org/docs/apache-airflow/stable/core-concepts/variables.html
The example for Variables
from datetime import datetime from airflow import DAG from airflow.decorators import task from airflow.operators.bash import BashOperator from airflow.models import Variable # A DAG represents a workflow, a collection of tasks with DAG(dag_id="var_test", start_date=datetime(2022, 1, 1), schedule="0 0 * * *", catchup=False) as dag: # Tasks are represented as operators hello = BashOperator(task_id="hello", bash_command="echo {{ var.value.var2 }}") @task() def airflow(): var1 = Variable.get("var1") print("from var1: ", var1) # Set dependencies between tasks hello >> airflow()
DAG Examples
Prerequest:
-
Apache Airflow
-
Build custom airflow docker image for supporting apache spark provider. Run
docker build --no-cache -t airflow-w-spark:0.1 .dockerfile
FROM apache/airflow:2.6.3-python3.9 USER root RUN apt-get update \ && apt-get install -y --no-install-recommends \ openjdk-11-jre-headless \ && apt-get autoremove -yqq --purge \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* USER airflow ENV JAVA_HOME=/usr/lib/jvm/java-11-openjdk-arm64 RUN pip install --no-cache-dir "apache-airflow==${AIRFLOW_VERSION}" apache-airflow-providers-apache-spark==2.1.3 -
Add
.envfor setting image variable and uid.AIRFLOW_UID= AIRFLOW_IMAGE_NAME=airflow-w-spark:0.1 -
Define Run
docker compose updocker-compose.yaml
version: '3.8' x-airflow-common: ...(skip) networks: - network services: postgres: ...(skip) networks: - network redis: ...(skip) networks: - network ...(skip) networks: network: driver: bridge name: airflow_network
-
-
Apache Spark Here we use bitnami spark docker image and set Spark network to the same as airflow's. Run
docker compose upto set up a spark cluster (1 master and 1 worker)docker-compose.yaml
# Copyright VMware, Inc. # SPDX-License-Identifier: APACHE-2.0 version: '2' services: spark: image: docker.io/bitnami/spark:3.4 environment: - SPARK_MODE=master - SPARK_RPC_AUTHENTICATION_ENABLED=no - SPARK_RPC_ENCRYPTION_ENABLED=no - SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no - SPARK_SSL_ENABLED=no - SPARK_USER=spark - PYSPARK_PYTHON=3.9 - PYSPARK_DRIVER_PYTHON=3.9 ports: - '8082:8080' networks: - network spark-worker: image: docker.io/bitnami/spark:3.4 environment: - SPARK_MODE=worker - SPARK_MASTER_URL=spark://spark:7077 - SPARK_WORKER_MEMORY=1G - SPARK_WORKER_CORES=1 - SPARK_RPC_AUTHENTICATION_ENABLED=no - SPARK_RPC_ENCRYPTION_ENABLED=no - SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no - SPARK_SSL_ENABLED=no - SPARK_USER=spark - PYSPARK_PYTHON=3.9 - PYSPARK_DRIVER_PYTHON=3.9 networks: - network networks: network: name: airflow_network external: true
Examples
-
Shell script
Sample code
# /opt/airflow/dag/shell/shell_local.py from datetime import datetime, timedelta # The DAG object; we'll need this to instantiate a DAG from airflow import DAG # Operators; we need this to operate! from airflow.operators.bash import BashOperator with DAG( "shell_local", # These args will get passed on to each operator # You can override them on a per-task basis during operator initialization default_args={ "depends_on_past": False, "email": ["[email protected]"], "email_on_failure": True, "email_on_retry": False, "retries": 1, "retry_delay": timedelta(minutes=5), }, description="A simple tutorial DAG", schedule=timedelta(minutes=1), start_date=datetime(2021, 1, 1), catchup=False, tags=["my_example"], ) as dag: # https://airflow.apache.org/docs/apache-airflow/stable/howto/operator/bash.html#jinja-template-not-found run_test_script = BashOperator( task_id="run_test_script", bash_command="/opt/airflow/dags/shell/test.sh ", ) run_test_script# /opt/airflow/dag/shell/test.sh echo "THIS IS INSIDE TEST.SH" -
Python script
Sample code
from datetime import datetime, timedelta # The DAG object; we'll need this to instantiate a DAG from airflow import DAG from airflow.operators.python import ExternalPythonOperator from python.local import show # Operators; we need this to operate! # from airflow.operators.bash import BashOperator with DAG( "python_local", # These args will get passed on to each operator # You can override them on a per-task basis during operator initialization default_args={ "depends_on_past": False, "email": ["[email protected]"], "email_on_failure": False, "email_on_retry": False, "retries": 1, "retry_delay": timedelta(minutes=5), }, description="A simple tutorial DAG", schedule=timedelta(minutes=10), start_date=datetime(2021, 1, 1), catchup=False, tags=["my_example"], max_active_runs=1 ) as dag: t1 = ExternalPythonOperator( task_id="show", python="/usr/local/bin/python", python_callable=show ) t1 -
SQL
- create MySQL connection in Apache Airflow web UI
Sample code
# /opt/airflow/dag/mysql/mysql_local.py from datetime import datetime, timedelta # The DAG object; we'll need this to instantiate a DAG from airflow import DAG from airflow.utils.trigger_rule import TriggerRule # Operators; we need this to operate! from airflow.providers.mysql.operators.mysql import MySqlOperator with DAG( "mysql_dag", # These args will get passed on to each operator # You can override them on a per-task basis during operator initialization default_args={ "depends_on_past": False, "email": ["[email protected]"], "email_on_failure": False, "email_on_retry": False, "retries": 1, "retry_delay": timedelta(minutes=1), }, description="A simple tutorial DAG", schedule=timedelta(minutes=3), start_date=datetime(2023, 7, 11), catchup=False, tags=["my_example"], ) as dag: create_table = MySqlOperator( task_id="create_table", sql=r"""CREATE TABLE `test1`.test_airflow ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL, `updated_at` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;""", dag=dag, mysql_conn_id="mysql_stg", ) create_table2 = MySqlOperator( task_id="create_table2", sql=r"""CREATE TABLE `test1`.test_airflow2 ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL, `updated_at` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;""", dag=dag, mysql_conn_id="mysql_stg", ) insert_task = MySqlOperator( task_id="insert", sql=r"""INSERT INTO `test1`.`test_airflow` (`name`) VALUES ('from airflow');""", dag=dag, mysql_conn_id="mysql_stg" ) drop_task1 = MySqlOperator( task_id="drop_test_airflow", sql=r"""DROP table `test1`.`test_airflow`;""", dag=dag, mysql_conn_id="mysql_stg", trigger_rule=TriggerRule.ONE_FAILED ) drop_task2 = MySqlOperator( task_id="drop_test_airflow2", sql=r"""DROP table `test1`.`test_airflow2`;""", dag=dag, mysql_conn_id="mysql_stg", trigger_rule=TriggerRule.ONE_FAILED ) [create_table, create_table2] >> insert_task # [create_table, create_table2] >> [drop_task1, drop_task2] [create_table, create_table2] >> drop_task1 [create_table, create_table2] >> drop_task2 -
Spark
- create Spark connection in Apache Airflow web UI
Sample code
from datetime import datetime, timedelta from textwrap import dedent # The DAG object; we'll need this to instantiate a DAG from airflow import DAG # Operators; we need this to operate! from airflow.providers.apache.spark.operators.spark_submit import SparkSubmitOperator with DAG( "audience_local", # These args will get passed on to each operator # You can override them on a per-task basis during operator initialization default_args={ "depends_on_past": False, "email": ["[email protected]"], "email_on_failure": False, "email_on_retry": False, "retries": 1, "retry_delay": timedelta(minutes=5), }, description="A simple tutorial DAG", schedule=timedelta(hours=1), start_date=datetime(2021, 1, 1), catchup=False, tags=["my_example"], max_active_runs=1 ) as dag: move_and_normalize = SparkSubmitOperator( application="/opt/airflow/dags/spark/pi.py", task_id="move_and_normalize", conn_id='spark_local', ) move_and_normalize
Some Important Points
-
Shared folder
- Use NFS (Network File System) and mount to scheduler and workers
- Copy dag folder to airflow docker image when build image. But it would need to build and re-deploy airflow every time when add/update dags.
Both scheduler and worker should access to dag folder. There are 2 way to do it.
-
Package dependency
- DockerOperator
- ExternalPythonOperator
- KubernateOperator
When import some 3rd party packages in dag/task python file, both scheduler and worker should install the packages. There some ways to avoid this kind of issue, e.g. run task inside a docker container, run python script with virtual environment or using Kubernate to execute tasks.
-
CI/CD
- One repositery
- git submodule
For deploying dags to production, when the amount of dags are few, could just copy the whole dag directory to docker image and deploy it. However, when the dag increase and cooperate with more team members, this way has some disadvantage. The first step could mount dag directory from host to Airflow container. Second, use git submodule to manage dags. It would be easilier to manage dags and do not need to re-deploy whole dag directory while there are some dag updates.
-
Install provider package
- Custom Dockerfile
It include default airflow providers in offical Airflow docker image. If dags depneds on other providers, the docker image should be customized by adding the provider like the dockerfile in above example prerequest which add spark provider.
Reference
- Document|Apache Airflow: https://airflow.apache.org/docs/apache-airflow/stable/index.html
- We’re All Using Airflow Wrong and How to Fix It: https://medium.com/bluecore-engineering/were-all-using-airflow-wrong-and-how-to-fix-it-a56f14cb0753
- Apache Airflow : 10 Rules to Make It Work: https://towardsdatascience.com/apache-airflow-in-2022-10-rules-to-make-it-work-b5ed130a51ad
- Apache airflow for beginners - MaxcoTec Learning |Youtube: https://www.youtube.com/playlist?list=PLzKRcZrsJN_xcKKyKn18K7sWu5TTtdywh